들어가며
서비스 출시가 완료되었기 때문에 이제는 운영을 고려한 개발을 진행해야 한다.
ex) API 버전 관리를 통해 API가 변경되어도 기존 API를 사용 가능할 수 있게 하기 (앱 배포 주기가 서버 배포 주기보다 길며, 앱 강제 업데이트를 하지 않으면 이전 버전을 쓰는 사람들도 많기 때문) 등 ...
그리고 서비스 장애가 발생하여도 이를 빠르게 파악하고, 최대한 빨리 서비스가 정상 동작하는 상태로 만드는 것이 중요하다.
장애 원인을 찾아 본질적 원인을 해결하는 것도 중요하지만, 사용자 입장에서 보았을 때 서비스가 뻗어보이지 않는 모습으로 보여주는 것이 중요하다.
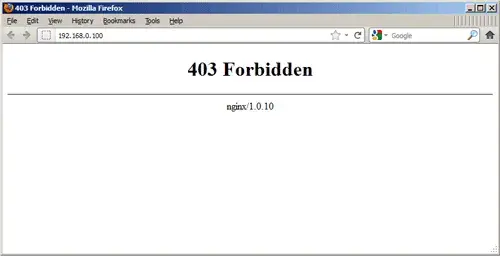
위와 같은 비정상적인 UI는 사용자들을 당황하게 만들 것이다.

이렇게 장애가 발생했음을 사용자에게 공지해주거나,

이렇게 장애가 발생한 부분만 에러 UI를 띄우고 나머지 기능은 사용 가능하도록 하는 것이 더 나을 것이다.
이번 포스트에서는 UI(프론트엔드)가 아닌 아키텍처의 측면에서 서비스 장애가 발생했을 때 어떻게 대처할지에 대해 알아보겠다.
DR, 그리고 RPO와 RTO
위에서 이야기한 것과 같이 자연재해나 인간의 행동(또는 실수, 휴먼에러)으로 인한 재해가 발생한 후 조직에서 IT 인프라에 대한 액세스 및 기능을 복원하는 것을 전문 용어로 DR(Disaster Recovery)라고 한다.
DR 전략을 수립하는데 고민해보아야 할 질문은 아래 2가지이다.
- 재생성하거나 손실되어도 되는 데이터의 양은 어느 정도인가?
- 얼마나 빨리 복구해야 하나? 가동 중지 시 비용은 얼마나 드나?

RPO(Recovery Point Objective)는 첫 번째 질문과 연관된 개념으로, 목표 복구 시점을 의미한다. 장애가 발생했을 때 비즈니스 연속을 위해 돌아갈 시점이 된다.
RTO(Recovery Time Objective)는 두 번째 질문과 연관된 개념으로, 장애가 발생했을 때 서비스를 원 상태로 복원하는데 소요되는 시간을 의미한다.
블라블라 프로젝트 아키텍처
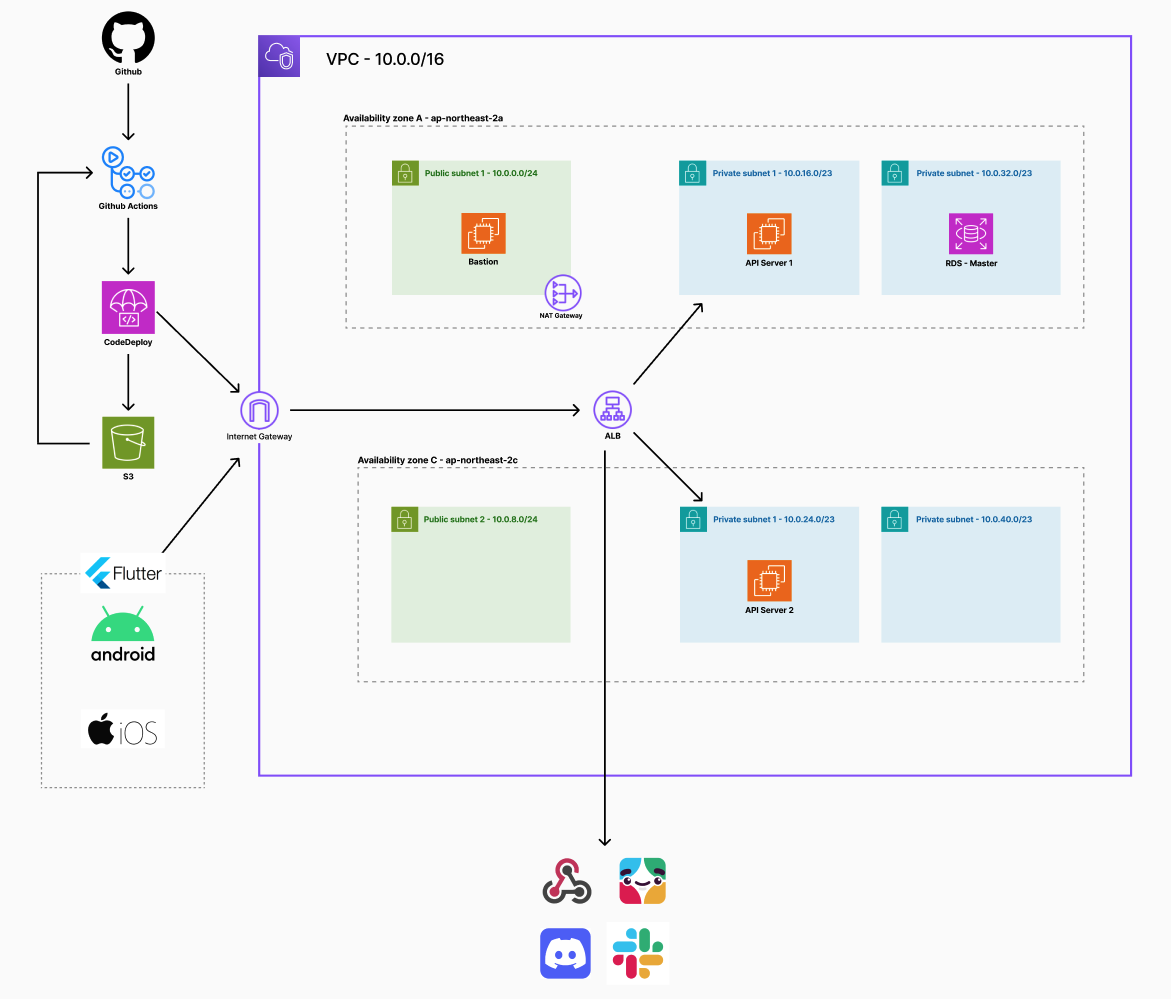
현재 진행중인 블라블라 프로젝트의 아키텍처 모습은 위와 같다. 지금 아키텍처의 문제점에 대해 짚어보면서, 어떻게 디벨롭할 수 있을지 고민해보자.
장애 감지하기
애플리케이션 측면
복구 시간을 줄이기 위해 장애 감지를 자동화하는 것이 좋다.
나는 logback의 error log를 디스코드와 연결하여 애플리케이션 레벨에서 발생한 에러에 대해 알림을 받고 있다. (https://leeeeeyeon-dev.tistory.com/3)
이렇게 로그를 디스코드/슬랙 등 소통 툴과 연동시키면 바로바로 확인할 수 있어서 좋다.
하지만, 전문적인 모니터링 도구가 아니기 때문에 로그를 검색하거나 분석하는 것에는 한계가 있다 🥹
Sentry, Grafana, Prometheus, EFK(ElasticSearch + Fluentd + Kibana) or ELK(ElasticSearch + Logstash + Kibana) 등을 이용하여 모니터링 시스템을 보다 정교하게 구축할 수 있다.
블라블라 프로젝트에는 아직 모니터링 시스템이 없는데, 우선 사용하기 쉬운 Sentry로 구축하고 Grafana나 Prometheus 같은거는 좀 더 공부해보려고 한다.
아키텍처 측면
현재 아키텍처에는 아키텍처 측면에서 발생하는 장애를 모니터링할 방법이 마련되어있지 않다 🥹
그렇기 때문에 ELB, EC2 등 AWS 서비스가 뻗게 됐을 때 빠른 파악이 불가능하다.
Cloudwatch와 AWS SNS를 사용하는 것이 가장 쉬운 방법일 것 같다.
백업 자주 하기
EC2라면 AMI 또는 Snapshot, RDS라면 Snapshot으로 주기적으로 백업을 하여 RPO를 최근으로 유지할 수 있을 것 같다.
고가용성 아키텍처로 보완
고가용성(High Availability, HA)은 서버, 네트워크, 프로그램 등의 정보 시스템이 상당히 오랜 기간 동안 지속적으로 정상 운영이 가능한 성질을 말한다.
쉽게 말해, 가용성이 높다는 뜻은 절대 고장 나지 않는다는 뜻이다.
현재 아키텍처를 고가용성으로 만들려면 어떤 방법을 취할 수 있을까?
EC2 - Auto Scaling Group 만들기

현재 아키텍처에서는 단순히 EC2 인스턴스를 2개 만들어뒀기 때문에 인스턴스 하나가 죽게 되면 수동으로 재시작을 해주어야 한다.
Auto Scaling Group을 만들면 인스턴스의 최소 및 최대 수를 정하여 Scale in/out이 가능하다.
CPU 점유율이 일정 수준을 넘을 때 오토 스케일링을 실행하거나, 트래픽이 몰리는 특정 시간에 실행하는 등 수준 유지, 일정 기반 등 다양한 조건 방법을 설정할 수 있다.
현재 아키텍처를 처음 구성할 때는 요금이 얼마나 나올지 예상이 안됐고 지금보다 AWS에 대한 이해도가 부족하여 Auto Scaling Group을 잘못 만들다가 요금 폭탄을 맞을까 두려워 설정하지 않았다.
하지만 Auto Scaling Group은 크게 어려운 설정이 아니기 때문에 현재 프로젝트에 추가하여도 될 것 같다!
아직은 유저가 많지 않기 때문에 Auto Scaling Group의 인스턴스 수는 현재와 동일하게 2개로 해도 충분할 것 같다.
RDS - Mulit AZ(이중화)
Active/Standby와 Master/Slave의 차이
- Acitve: 평상시 Request를 받아 처리할 수 있는 시스템
- Standby(= Passive = Backup): Acitve 시스템에 장애가 발생했을 때 Request를 처리할 수 있는 시스템
- Master: Write를 처리할 수 있는 Active 시스템
- Slave: Read를 처리할 수 있는 Active 시스템
내가 사용할 전략은 Active/Standby 전략이다!
나는 2가지 개념의 차이를 모르고 DB 이중화 == Master/Slave라고 표현했는데 앞으로는 명확한 표현을 사용해야겠다 ㅎㅎ ...
RDS 설정에서 가용성 및 내구성 > 다중 AZ 배포 > 대기 인스턴스 생성을 통해 Standby 인스턴스를 둘 수 있다.
로드밸런싱이 제대로 이루어지지 않는다면?
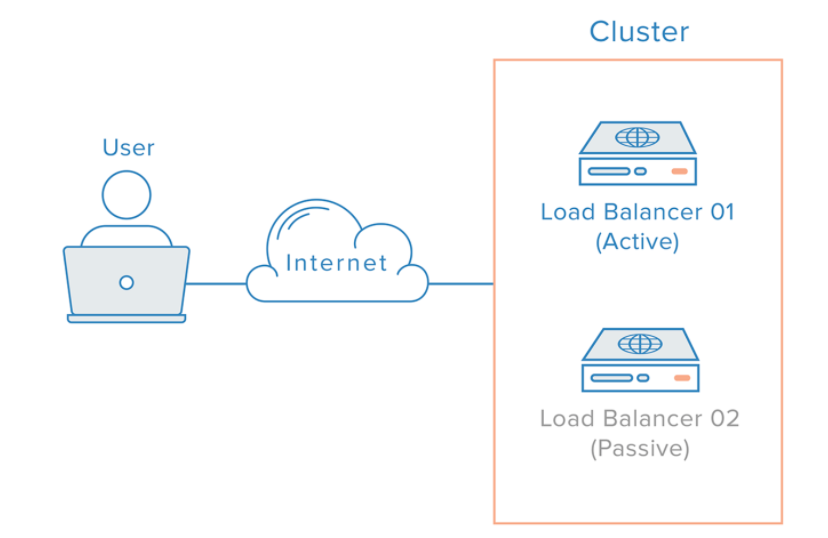
찾아보니 로드밸런서도 서버나 DB처럼 Active/Passive 전략으로 이중화하는 방법이 존재한다.
- 두 로드 밸런서를 서로 Health Check를 한다.
- Active 로드 밸런서가 동작하지 않으면 가상 IP(Virtual IP)를 Passive Load Balancer로 변경한다.
- Passive Load Balancer로 운영한다.

로드밸런서도 이중화되는지 몰랐는데 오늘 또 알아간다 ...
만약 로드밸런서에 장애가 생긴다면, 하나의 인스턴스로 트래픽이 몰리게 될 것이다.
이를 해결할 수 있는 방법이
- 로드밸런서를 이중화하여 문제를 예방하기
- 트래픽이 몰리는 인스턴스를 Scale up하여 몰려드는 트래픽에 대처하기 (문제를 해결하기)
인 것 같다.
현재 상황에서는
- 나의 네트워크 지식 부족
- 관리 포인트 증가
때문에 이번 프로젝트에서는 로드밸런서 이중화보다는 Scale up 방식을 채택해야 할 것 같다.
논리적 분리보다는 물리적 분리
Spring boot 애플리케이션 서버의 경우 포트를 2개로 분리하여 사용하는 방식으로 개발/운영 서버를 운영하고 있고, RDS의 경우 schema를 분리하여 사용하고 있다.
논리적 분리의 경우, 개발 환경을 편집하다가 실수를 하게 될 때 운영 환경에도 영향을 미칠 수 있으므로 불안정한 방식이다. 그렇기 때문에 개발 환경과 운영 환경을 물리적으로 분리해주는 것이 보다 안전하다.
하지만 그렇게 할 경우 리소스가 2배로 들고, IaC가 없는 지금 상황에서 개발 환경과 운영 환경을 완벽하게 일치시킬 자신이 없기 때문에 이번 프로젝트에서는 사용하지 않을 것 같다.
마치며
- 고가용성을 위해 아키텍처를 고도화하는 방법에는 끝도 없는 것 같다 ... 이번 고민 과정을 통해 관리 포인트가 늘어나는 것을 보면서 IaC의 중요성을 조금이나마 느낄 수 있었던 것 같다.
- 서비스를 만들 때는 기술과 비용 사이의 trade off에 대해 끊임없이 고민해야 하는 것 같다. 둘 사이의 타협점을 찾기 위해 현실적인 계획 수립(모니터링 지표 선정이나 장애 복구 목표 등 ...)이 중요한 것 같다.
- 최근 공부하고 있는 쿠버네티스를 사용하는 것도 관리 포인트를 줄여주는데 도움이 될 수 있을 것 같다. 멀티 모듈이나 MSA 등 관심에 따라 환경을 분리하는 것이 중요해질수록 도커나 쿠버네티스와 같은 컨테이너 기술은 필수가 될 것 같다고 생각되고, 나도 얼른 컨테이너를 능숙하게 쓸 수 있도록 열심히 공부해야 할 것 같다.
👍 Reference
- https://docs.aws.amazon.com/ko_kr/wellarchitected/latest/reliability-pillar/disaster-recovery-dr-objectives.html
- https://milhouse93.tistory.com/172
- https://aws.amazon.com/ko/blogs/tech/disaster-recovery-dr-architecture-on-aws-part-i-strategies-for-recovery-in-the-cloud-1/
- https://aws.amazon.com/ko/blogs/tech/disaster-recovery-dr-architecture-on-aws-part-i-strategies-for-recovery-in-the-cloud-2/
- https://inpa.tistory.com/entry/AWS-%F0%9F%93%9A-EC2-%EC%98%A4%ED%86%A0-%EC%8A%A4%EC%BC%80%EC%9D%BC%EB%A7%81-ELB-%EB%A1%9C%EB%93%9C-%EB%B0%B8%EB%9F%B0%EC%84%9C-%EA%B0%9C%EB%85%90-%EA%B5%AC%EC%B6%95-%EC%84%B8%ED%8C%85-%F0%9F%92%AF-%EC%A0%95%EB%A6%AC
- https://dev2som.tistory.com/42